Fall semester of my Junior year at Virginia Tech was more a laid-back one when compared to my earlier semesters – mainly due to the fact that I was a year ahead of schedule and most, if not all, of my hard classes were behind me. I took the solid amount of free time that I had to start researching new and interesting computer science topics, while building on the skills I had learned previously either at my internship with Cox, or through the work I had done by myself. After coming up with a couple of different ideas, I settled on a basic card game, twisted in such a way as to challenge what I knew and force me to learn some new and interesting concepts.
Essentially, my goal was to create a multiplayer standard 52 card game that was able to support any rules the players decided to enforce. The idea was to create a simple backend so that I could have the liberty on focusing on the more challenging and new concepts like communicating with a central game server. I also wanted to test my abilities in making a backend in C, as it is well known that lower level languages, like C and C++, are great for games due to their relatively fast execution times. However, making all other aspects of a game in C (i.e. rendering) can be rather frustrating and time consuming, so I also decided to code the frontend in another language. As such, I settled on python/pygame. Finally, as I wanted to make the game multiplayer, I needed to include a server framework that was able to communicate with n many clients at a time, while still being able to interface with the backend C code. After doing some research, I decided on ASP.NET, as I am generally unfamiliar with C# and the .NET framework, and wanted to use the opportunity to learn something new instead of falling back on a framework I’m more comfortable with. Using C# also allowed me to interface with the backend incredibly easily (detailed later). I decided to upload the server on AWS/EC2, as I’m always looking for an excuse to learn more about the Cloud/AWS and practice using it.
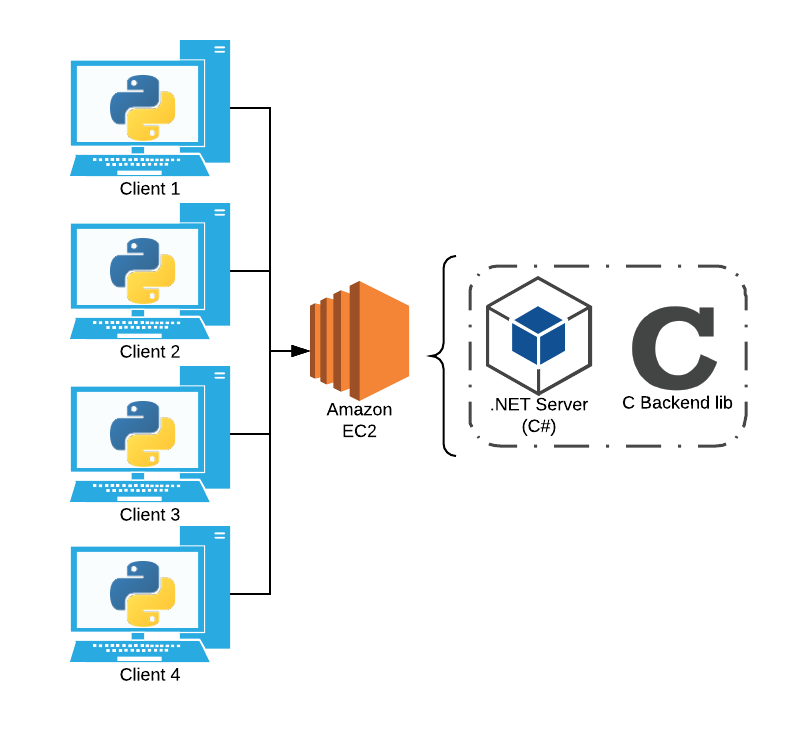 The final architecture of the card game project.
The final architecture of the card game project.
Coding the C backend was the easiest part of the project – mainly due to my comfort level with the language (thanks to the many difficult low-level programming courses taught by Virginia Tech), but also due to the nature of the project. The game is fairly simple; there exists only a couple of noteworthy objects/data structures. The main deck, the cards on the table, and the cards in each of the player’s hands. All of these objects can be represented as a Deck, each containing Cards. I created the Deck data structure as a hybrid between a stack and an array list. It supports popping and pushing, as drawing from a deck usually entails popping from one deck and pushing it onto another, but the need for placing or picking cards from specific indices was also necessary, as a player picks and chooses specific cards to move onto or into their hand from the table. As of right now, the backend supports 4 basic functions – drawing from the main deck to the table, drawing from the main deck to a player’s hand, picking a card up from the table and placing it into a player’s hand, and placing a card from a player’s hand onto the table. Keeping it relatively simple, at least for the time being, allowed me to write up this portion of the project quickly and move on to the newer and more challenging parts of this project. I definitely plan on revisiting this section and fleshing it out to add more functionality later down the line.
Next came creating the server and wrapper for the backend. Like I stated before, however, this was relatively easy, as the choice for C# made interfacing the C backend easy (through DllImport) and the .NET framework allowed for a speedy standing-up of a basic RESTful web API (through MVC). Essentially, the client makes requests on various endpoints depending on the method they want to invoke. All I really had to do was create endpoints for each of the 4 functions described in the paragraph above. Other than that, I created register/unregister endpoints for when a player joins or leaves the session (mainly to ensure that the number of players didn’t exceed the maximum of 4, and to assign each player a specific player id), and basic start/terminate endpoints. After creating the C# server, all that was left was to publish it on an AWS EC2 instance, which admittedly took some time as I was unfamiliar with how to do so, but was achievable in the end after some time and googling.
Finally came creating the frontend in Python. Thankfully, interfacing the server was relatively easy due to the urllib library. As a result, I really just needed to focus on getting the correct information from the server and translating it into something that could be easily understood and rendered using pygame. I achieved this by adding an endpoint to the server that retrieved a JSON object of the entire table (including the main deck, the cards on the table, and each of the hands). The python code regularly makes checks to this endpoint and references it against a stored version. If they differ, the local versions of these decks are changed to reflect the differences. All I really needed to do at that point was render the cards and come up with an intuitive way to activate the backend functions. I took inspiration from the popular online card game Hearthstone and implemented a dragging feature, where players can click and drag cards from their hand to the table or visa-versa.
 The current status of the python client, with 4 players connected to the central server. You can see the main deck represented in the middle of the screen as the stack of non-visible cards, and the on table cards represented as the stack of visible cards. Each of the hands are also present, with only the current player’s hand being visible.
The current status of the python client, with 4 players connected to the central server. You can see the main deck represented in the middle of the screen as the stack of non-visible cards, and the on table cards represented as the stack of visible cards. Each of the hands are also present, with only the current player’s hand being visible.
I still have much I want to achieve with this project. After an initial play test with friends we discussed a couple of features that would be good to include later down the line. For instance, the ability to show cards from one’s hand without having to place it on the table, being able to discretely trade cards between players, and the inclusion of a discard pile. I’m eager to continue optimizing and working on this to see where I am able to take the final product. If you’d like to see the code for this project, you can view it on github here.
Thanks for reading! If you have any questions or comments, feel free to write them below or email me at [email protected].

 The completed frame.
The completed frame.
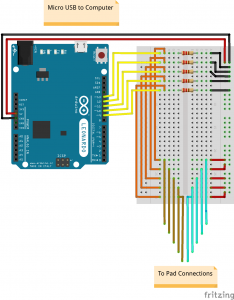 The Arduino circuit for this build. It’s set up in such a way that the pins read low when the pad is not engaged and high when engaged.
The Arduino circuit for this build. It’s set up in such a way that the pins read low when the pad is not engaged and high when engaged.  The final version of the pad. You can see the Arduino hooked up at the top of the pad. As of right now, I’m just using a cardboard box to house everything
The final version of the pad. You can see the Arduino hooked up at the top of the pad. As of right now, I’m just using a cardboard box to house everything The original plan. It involved routing the domain using Route 53 through Cloudfront (for https) and to an S3 bucket hosting html files.
The original plan. It involved routing the domain using Route 53 through Cloudfront (for https) and to an S3 bucket hosting html files. The final implementation. Instead of routing through Cloudfront and then to S3, it was routed directly to an EC2 instance running WordPress with LEGO (Let’s Encrypt) for SSL/https.
The final implementation. Instead of routing through Cloudfront and then to S3, it was routed directly to an EC2 instance running WordPress with LEGO (Let’s Encrypt) for SSL/https.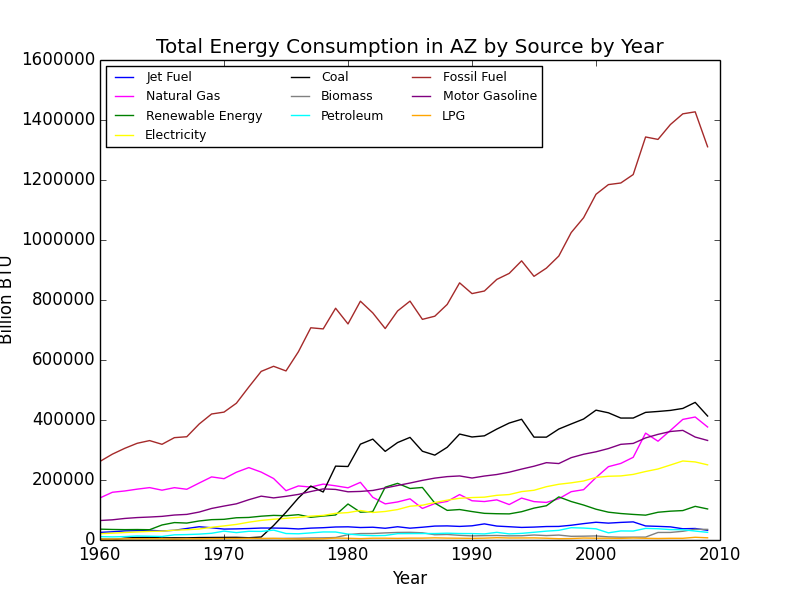

 Excerpt from our final paper detailing the values of the C conversion constant and giving Arizona’s numbers for 2009.
Excerpt from our final paper detailing the values of the C conversion constant and giving Arizona’s numbers for 2009.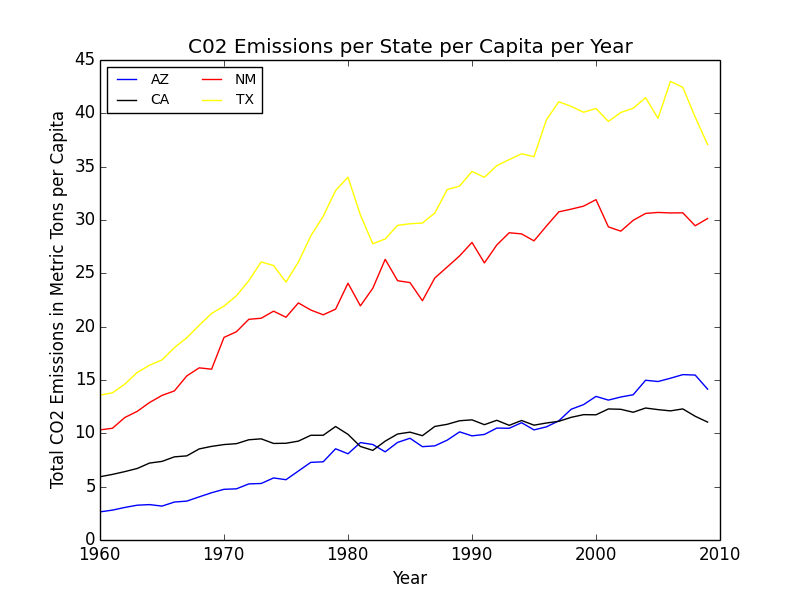


Recent Comments