The 2015 school year was when I began dabbling around AI. The idea always amazed me. Everything from movie depictions of them to the real practical uses they have in modern day life was interesting, and I wanted to know more about it.
After my Chess project, I wanted to become a little more serious in my research surrounding artificial intelligence. I looked up everything from examples of how it was used in day to day life to videos of lectures by college professors. I learned a lot about the concept of reinforcement learning through these lectures and even watching college Thesis projects, making me want to program something to test out the idea.
First, however, a very brief overview of my current understanding of reinforcement learning. Reinforcement learning is a system in which the AI learns about the environment it’s put in through a system of actions and states. The ai is rewarded or punished through the various states (depending on whether you want to maximize utility or minimize cost, either way is fine, but for my example I will be using a reward system) for good actions versus bad actions, but the AI doesn’t know which actions are good or bad until it experiences them. Thus, after a long time, the AI should begin to gravitate towards actions that garner it the largest sum reward.
Alright, now to my project. I decided to go with something simple and intuitive to explore the concept of reinforcement learning through creating an artificial intelligence that would find the quickest path to an exit in a predefined maze. As mentioned before, the AI started with knowing absolutely nothing about the maze it was placed in, and must learn everything from scratch.
Original board displaying reward values for each tile (currently 0 because the AI doesn’t know which tiles are good and bad yet). The blue tile is the current position of the runner (controlled by the AI) and the green tile is the exit.
The reward system for the AI essentially takes in all of the rewards of the tiles it visited and sums it together, divides that number by the amount of tiles visited, and uses that value to update the reward value for all of the tiles it visited. The tiles takes that value and averages it into all of its previous rewards given from previous trials. The AI gets a heavy reward boost for completing the maze faster than before, and a heavy punishment if it was slower (increase/decrease overall reward by a factor of 2). Thus, over time, the AI slowly becomes better and better at solving the maze.
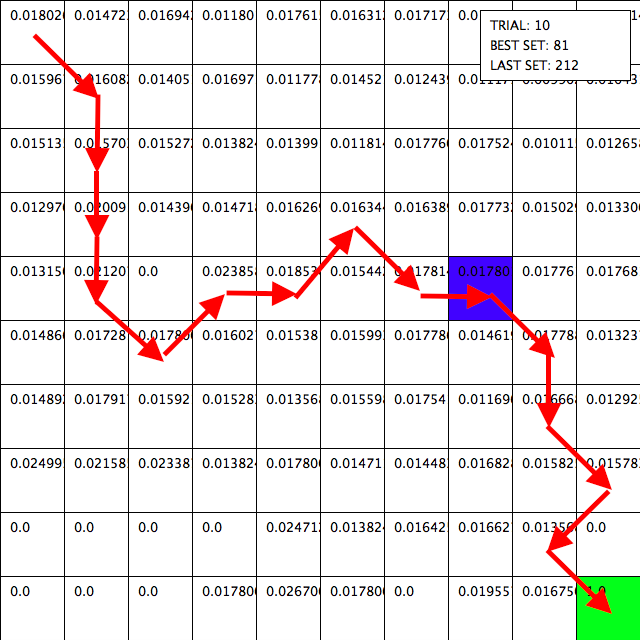
The 10th trial. You can see the general path the AI takes (tiles with the highest reward) is rather sporadic.
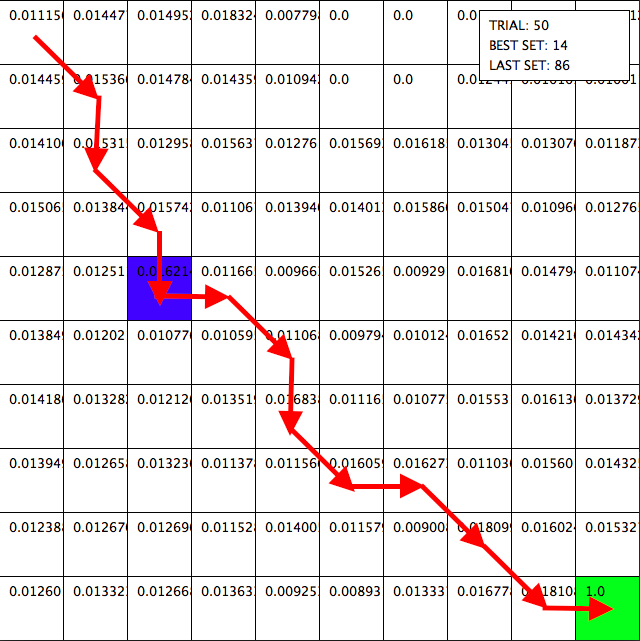
The 50th trial. The AI has begun to iron out all the kinks in the path, but it isn’t yet the most efficient.
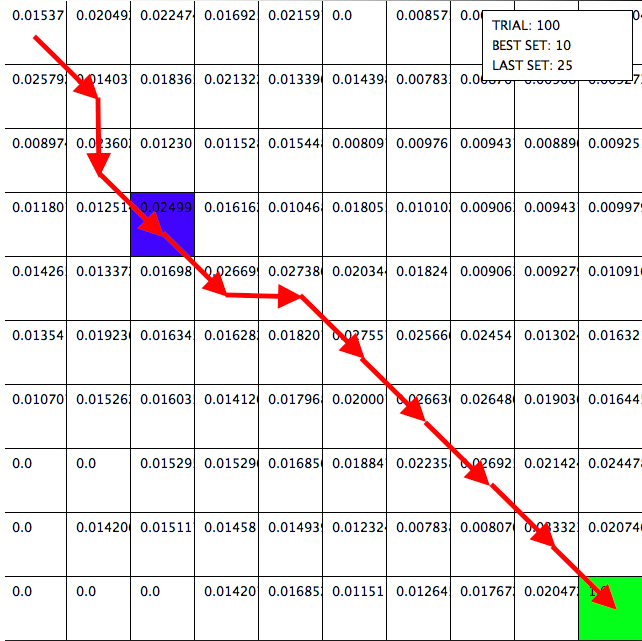
The 100th trial. You can see the AI has almost found the most efficient path.
I heavily enjoyed this project, as watching something learn, especially a program, is really interesting. I’m really excited to see where I can take this in the future.
If you want to play around with this, you can get the source code here (Java, 24kb): https://drive.google.com/file/d/0Bz_0wgRmDpKqNUVpTFFQdUNaaUk/view?usp=sharing
Recent Comments